Training on Mass Surveillance Datasets Provides No Empirical Benefits
AIES, 2026
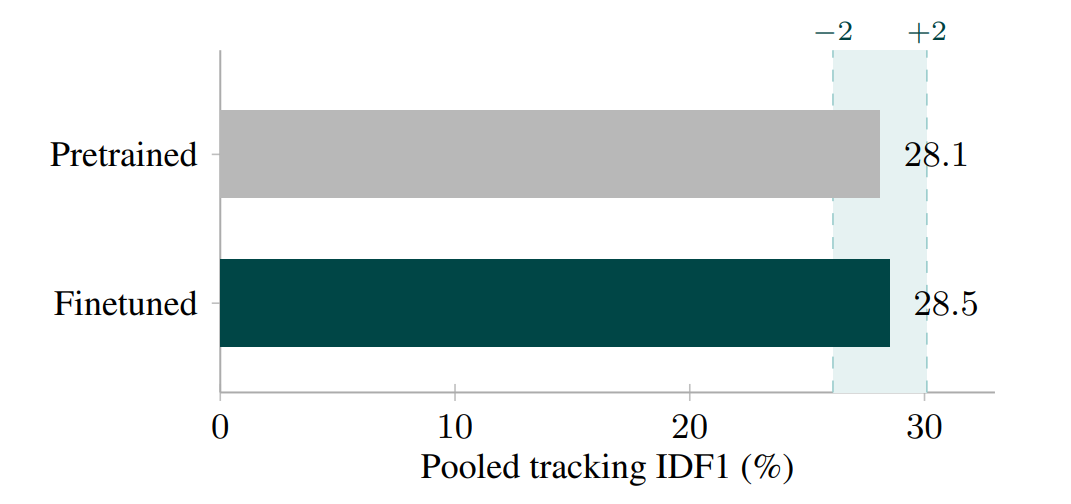
In this paper, I demonstrated the ineffectiveness of ReID datasets which is being deployed in surveillance pipelines.
I am Pranav, a PhD researcher at the University of Hamburg, where I work in Trustworthy AI Group. I am an interdiscplinary researcher working on AI ethics.
My full name is Pranav Agrawal, but I prefer to be called Pranav A. For academic publications I use the name A Pranav. I use he/him or they/them pronouns. You can reach me at cs.pranav.a (at) gmail.com.
My main research interest is inclusive AI policymaking, which sits at the intersection of AI ethics, NLP, ML, and HCI. My current work focuses on resisting surveillance AI. My research asks the question: How can technology and society hold each other accountable in the policies they jointly shape? This comprises questioning sociotechnical systems:
At the University of Hamburg, I teach Ethics and Modern AI, Text Analysis, and Trustworthy AI. I supervise bachelor's and master's theses and run student projects.
Below are some of the research papers I have worked on. My work has been published at top-tier conferences and received paper awards.
In this paper, I demonstrated the ineffectiveness of ReID datasets which is being deployed in surveillance pipelines.
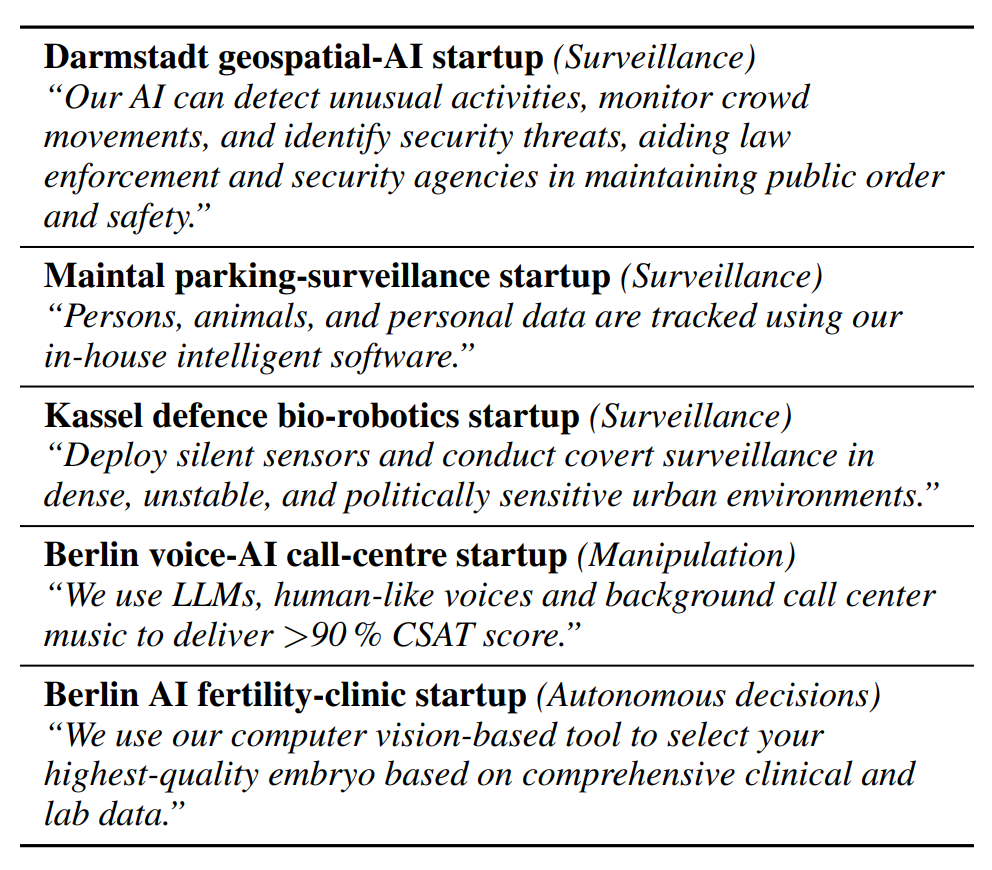
We audited marketing materials of 100 startups in Germany and discussed the perception of exaggerated claims (AI-washing) with experts and public.
An early account of my doctoral dissertation on critiques of current policymaking related to surveillance based AI.
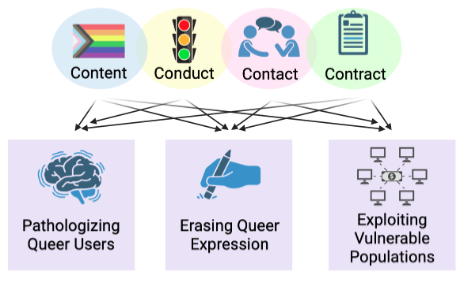
Content filtering systems disproportionately remove mentions of marginalized groups while failing to catch genuinely harmful material, creating a form of epistemic erasure in language model training and deployment.
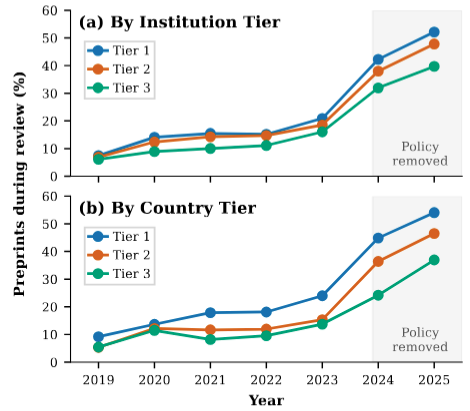
This mixed-methods paper surveys and interviews NLP researchers about ACL's anonymity policy removal and quantitatively analyzes how preprint visibility and author recognition bias review scores and quality across institutional tiers.
Having proactive name change policies leads to inclusive publishing with better citation quality.
Understanding the impact of AI requires more than technical expertise, but also listening to the communities affected by these technologies.
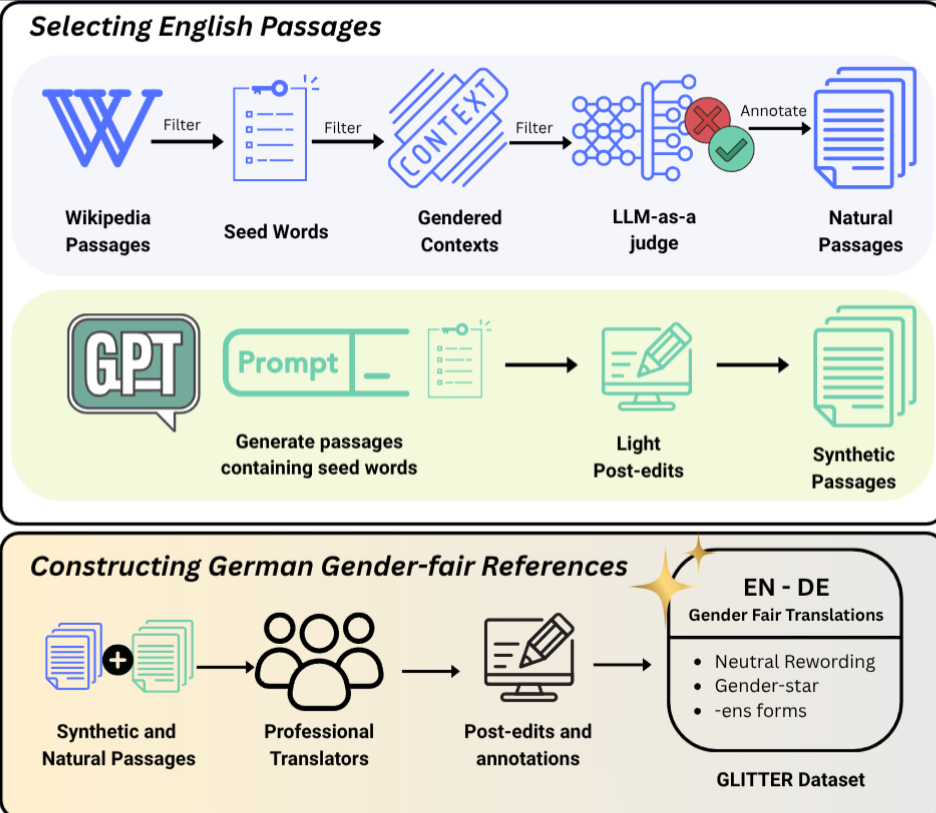
We introduce Glitter, an English-German benchmark featuring extended passages with professional translations implementing three gender-fair alternatives. Our experiments reveal significant limitations in state-of-the-art language models, which default to masculine generics and rarely produce gender-fair translations even when explicitly instructed.
We expand Yann LeCun's 'cake that is intelligence' analogy to the full life-cycle of AI systems, from sourcing data to evaluation and distribution. We describe each step's social ramifications and provide actionable recommendations for increased participation in AI discourse.
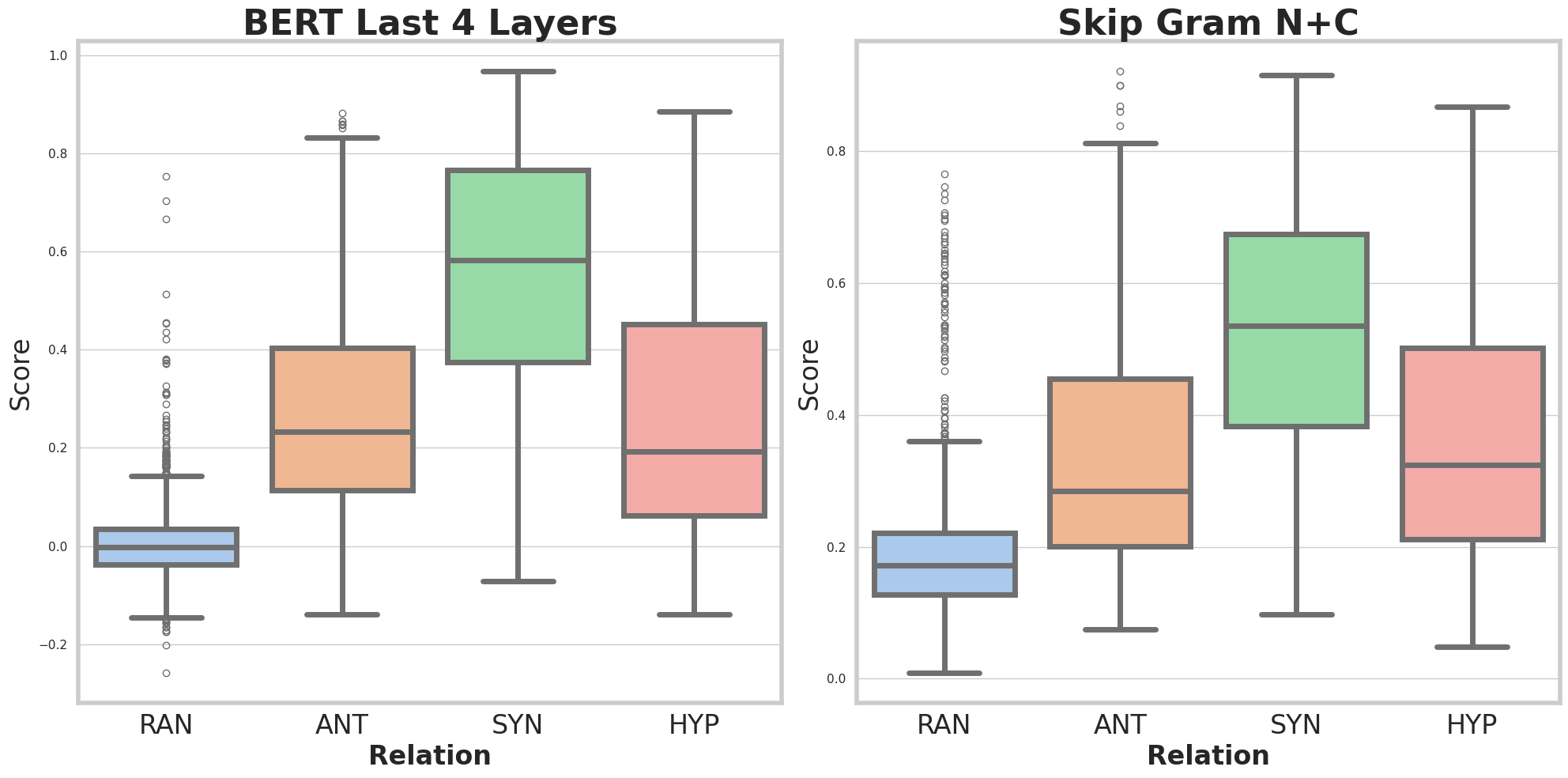
Emperical comparisions on character based models against word based models on common Chinese semantic benchmarks.
Community-led participatory design case study of Queer in AI contributed lessons on decentralization, building community aid, empowering marginalized groups, and critiquing poor participatory practices.
Queer in AI provides a tutorial for diversity & inclusion organizers on making virtual conferences more queer-friendly through inclusivity based on their community's experiences with marginalization.
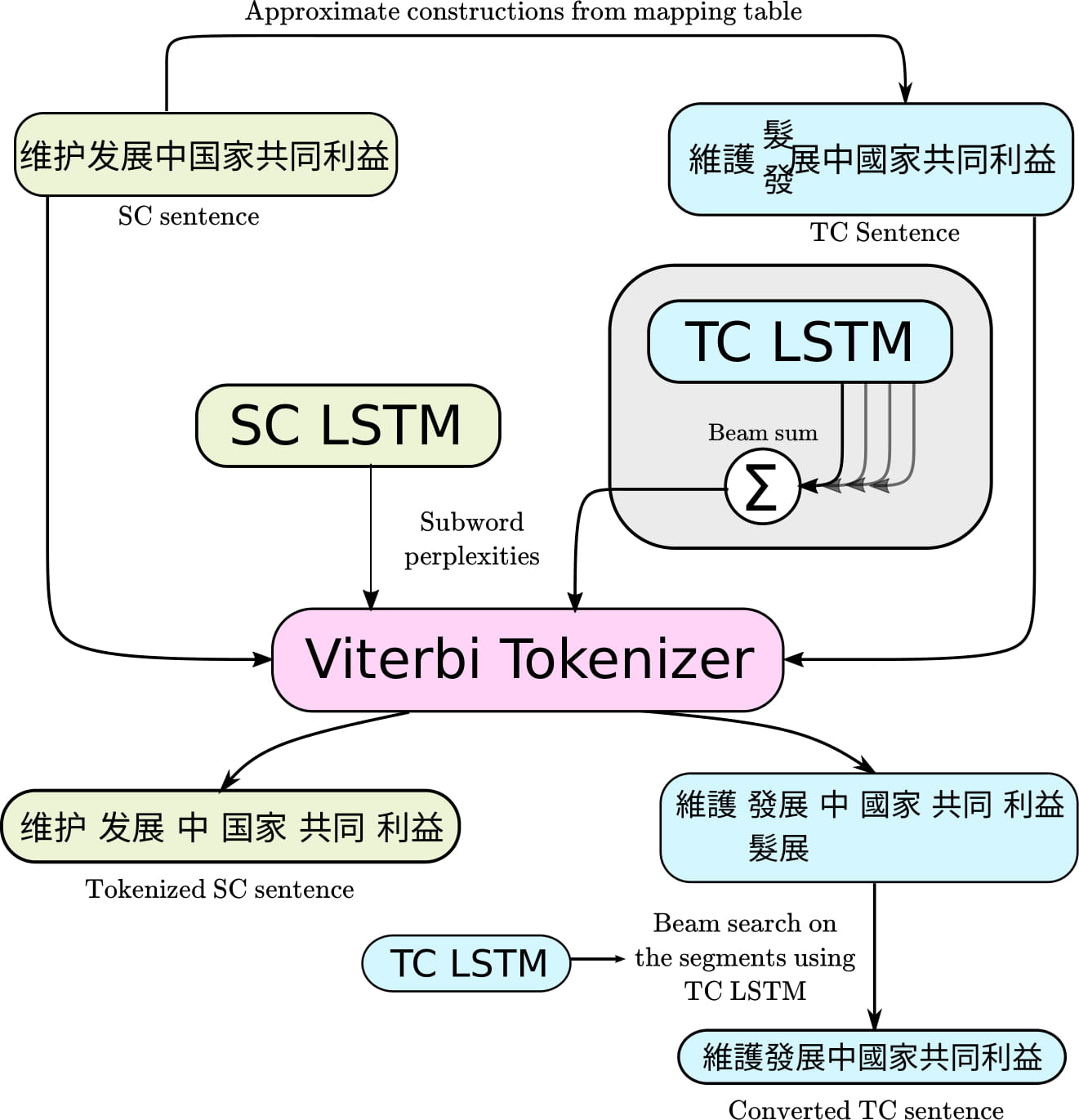
The paper contributes a contextual subword segmentation method along with benchmark datasets that outperformed previous Chinese character conversion approaches by 6 points in accuracy, especially for code-mixing and names entities.
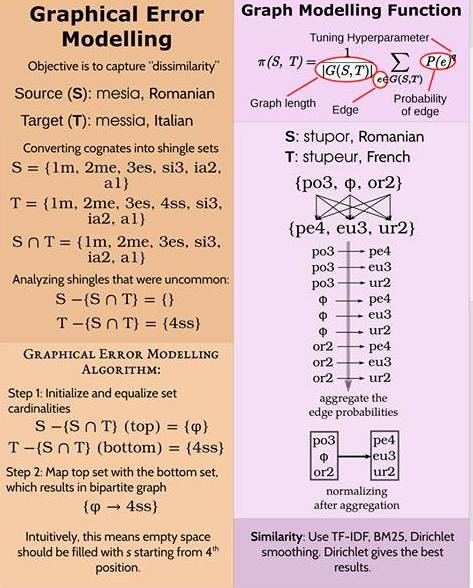
The paper contributes information retrieval ranking functions with heuristics like positional tokenization and graphical error modelling to the problem of cognate detection.
I am a co-founder of Queer in NLP, co-organize the Identity-Aware AI workshop series, and have served as D&I chair at *CL conferences.
Outside of research, I do improv comedy and lead an improv group at UHH called Tupananchiskamas. If you would like to join us, shoot us an email.
I also teach meditation, in particular Insight Dialogue, a practice that brings mindfulness into conversation. If you are interested in learning, let me know.